在当今数字时代,编程已经变成了一种基础技能。无论是为了职业发展,还是单纯的兴趣,学习编程都能为我们打开一扇通往新世界的窗。而Tokenim作为一种新兴的编程工具,吸引了越来越多的开发者关注。它不仅简单易学,而且功能强大,适合各个层次的需求。
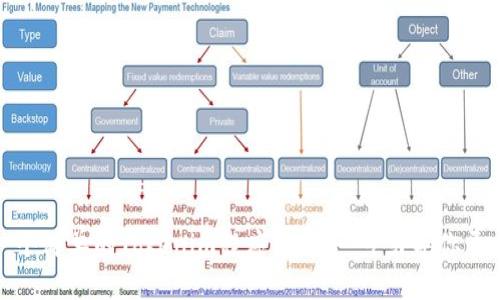
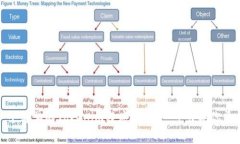
Tokenim是一种基于Token化处理的程序,它能帮助用户快速处理大量数据,并将数据转换成可分析的格式。通过Tokenim,开发者不仅可以简化数据输入与输出的过程,还能在较短的时间内完成复杂的计算。
在本文中,我们将逐步指导你如何创建一个简单的Tokenim程序,帮助你快速入门。无论你是编程的初学者,还是已经有一定基础的开发者,都会在这个过程中收获不少。
在开始创建Tokenim程序之前,我们需要为编程搭建一个合适的环境。首先,请确保你的计算机上安装了Python,这是我们使用的主要编程语言。而选择Python的原因是它简洁的语法和强大的库支持,使新手也能快速上手。
如果你还没有安装Python,可以从[Python官网](https://www.python.org/downloads/)下载并进行安装。安装过程非常简单,只需按照提示一步步完成即可。

除了Python本身,我们还需要一些额外的库来实现Tokenim的功能。我们将使用`tokenize`库来处理文本的Token化,利用`nltk`库进行自然语言处理。你可以通过以下命令在终端或命令行中安装这些库:
pip install tokenize nltk完成安装后,你将有足够的工具来开展Tokenim程序的开发。
现在,我们已经完成了环境设置,接下来便是实际的编码过程。打开你的IDE(例如PyCharm或VSCode),新建一个Python文件,例如`tokenim.py`。在这个文件中,我们将逐步添加代码。
下面是基础的Tokenim程序代码示例:
import nltk
from nltk.tokenize import word_tokenize
# 确保已经下载了punkt数据包
nltk.download('punkt')
def tokenize_text(input_text):
tokens = word_tokenize(input_text)
return tokens
if __name__ == "__main__":
text = input("请输入你想要Token化的文本:")
tokens = tokenize_text(text)
print("Token化结果:", tokens)
以上代码实现了将输入的文本进行Token化,并输出Token的结果。每个步骤都经过精心设计,以确保程序能够顺利运行。
代码编写完成后,保存文件并在终端中运行该程序。你会看到一个提示,要求输入文本。输入任何你想要处理的句子,例如“编程是一项有趣的技能”,然后按回车键。
程序将输出Token化的结果,类似于:
Token化结果: ['编程', '是', '一项', '有趣', '的', '技能']
通过这个简单的测试,你可以验证Tokenim程序是否正常工作。遇到问题时,仔细检查代码,确保所有库都已正确安装。
一旦你掌握了基础的Tokenim功能,你就可以开始思考如何扩展与增强它。比如,你可以加入更多的文本处理功能,如去除停用词、进行词干提取等。想象一下,这样的功能无疑能让你的Tokenim程序更加完美。
例如,利用`nltk`库中的停用词列表,你可以轻松地扩展程序,去除文本中的常用词:
from nltk.corpus import stopwords
nltk.download('stopwords')
def remove_stopwords(tokens):
stop_words = set(stopwords.words('chinese'))
filtered_tokens = [w for w in tokens if not w in stop_words]
return filtered_tokens
在原有的Tokenize流程中,调用这个新函数,就能轻松过滤掉无效信息,使得该程序变得更加精准高效。
经过上述步骤,你已经成功创建了一个简单的Tokenim程序,也对其功能有了初步的理解。编程的旅程无疑是充满挑战的,但每次的学习与尝试都会让你更加接近目标。
未来,你可以继续深入研究Tokenim的应用,或将其与其他技术结合,实现更复杂的功能。记住,编程是一门艺术,勇于探索,乐于创新,最终你会在这个领域找到属于自己的位置。
希望通过这篇文章,你能对Tokenim的创建过程有更深入的了解。不论你是刚踏入编程世界的初学者,还是希望提升技能的开发者,Tokenim都能成为你探索更多可能性的起点。不要畏惧挑战,尽情享受编程带来的乐趣吧!



leave a reply